Appearance
TimeMixer 深度学习笔记
TimeMixer: Decomposable Multiscale Mixing for Time Series Forecasting(ICLR 2024)
一句话定位
TimeMixer = 多尺度分解 + 季节 Bottom-Up 混合 + 趋势 Top-Down 混合 + 多预测器集成 → 解决真实时序中细/粗尺度信息纠缠、无法同时捕捉微观季节与宏观趋势的问题
核心洞见:时间序列在不同采样尺度下呈现不同模式——细粒度含高频季节细节,粗粒度含低频宏观趋势。将二者分离并双向融合,比直接混合多尺度更有效。
零、前置知识
0.1 必须了解(缺少则看不懂正文)
| 概念 | 关键内容 | 推荐入口 |
|---|---|---|
| 序列分解 (Seasonal-Trend Decomp) | 用移动平均将时序拆成趋势项和季节项;Autoformer 引入深度学习 | [[Autoformer-深度学习笔记]] |
| MLP-Mixer 思想 | 用纯线性层在 token 维和 channel 维交替混合;不依赖注意力 | [MLP-Mixer, NeurIPS 2021] |
| 下采样 / 均值池化 | AvgPool 将序列长度减半,粒度变粗;PyTorch: nn.AvgPool1d | — |
| 残差连接 | 输出 = 输入 + f(输入),防止梯度消失 | — |
| 长期/短期预测评估指标 | MSE/MAE (长期);SMAPE/MASE/OWA (短期 M4) | — |
0.2 推荐了解
| 概念 | 为什么推荐 |
|---|---|
| PatchTST | 同期 SOTA;TimeMixer 在 Weather 上以 9.4% MSE 优势超越它 |
| DLinear | 极简线性分解基线;TimeMixer 改变了纯线性思路,加入多尺度 |
| TimesNet | 将 1D 时序变换为 2D 处理;对比理解"多尺度"的不同实现方式 |
| Pyraformer / SCINet | 同为多尺度方法,但不使用历史信息的多尺度表征 |
0.3 背景:前作留下了什么问题
分解派(Autoformer, DLinear):只在单一尺度做季节-趋势分解,忽略了不同采样频率下模式的本质差异。
多尺度派(Pyraformer, SCINet):虽然引入了多尺度,但不同尺度的预测能力没有被显式地互补利用——各尺度信息提取和未来预测是割裂的。
核心矛盾:真实时序(如流量数据)的小时粒度记录日内变化,日粒度则突出假日波动,宏观经济趋势主导年粒度——单尺度视角必然丢失信息。TimeMixer 要解决的正是:如何同时利用多尺度的互补信息,且在历史提取和未来预测两个阶段都有效?
一、问题定义
给定多变量时间序列
| 符号 | 含义 |
|---|---|
| 历史观测长度(look-back window) | |
| 预测长度(prediction horizon) | |
| 变量数(variates) | |
| 下采样尺度数(长期取 3,短期取 1) | |
| PDM 堆叠层数(默认 2) | |
| 隐藏维度(16 ~ 128) | |
| 第 | |
| 第 |
二、整体架构鸟瞰
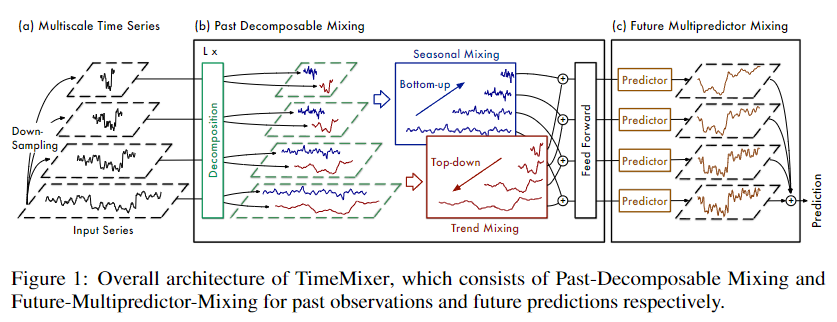
论文 Figure 1:TimeMixer 整体架构,由三部分组成。 (a) 多尺度时间序列:输入经过均值池化下采样 M 次,得到从细粒度(scale 0,完整序列)到粗粒度(scale M,最短序列)共 M+1 个尺度。 (b) Past-Decomposable-Mixing (PDM):对每个尺度做季节-趋势分解,季节成分做 Bottom-Up(细→粗)混合,趋势成分做 Top-Down(粗→细)混合,再加前馈残差;叠加 L 层。 (c) Future-Multipredictor-Mixing (FMM):每个尺度独立使用线性预测器,最终求和集成为预测结果。

颜色说明:蓝=输入,橙=下采样/嵌入,红=序列分解,紫=季节 Bottom-Up 混合,棕=趋势 Top-Down 混合,青=前馈残差,绿=预测器/输出。
数据流简述:
x ∈ ℝ^(P×C)
↓ AvgPool × M
{x₀, x₁, ..., x_M} 多尺度序列
↓ Embedding(线性投影到 d_model 维)
X⁰ 初始多尺度特征
↓ PDM × L 层
每层:SeriesDecomp → S-Mix(bottom-up) + T-Mix(top-down) → FeedForward → 残差
X^L 混合后的多尺度过去表征
↓ FMM(M+1 个独立预测器,求和集成)
x̂ ∈ ℝ^(F×C) 最终预测三、多尺度混合架构(Multiscale Mixing)
3.1 下采样生成多尺度
对历史观测
:最细粒度,保留全部高频细节 :最粗粒度,长度仅 ,只剩宏观趋势
嵌入:
3.2 堆叠 PDM 块
四、Past-Decomposable-Mixing (PDM) 详解
PDM 是 TimeMixer 的核心创新,其设计动机是:即使在最粗尺度,季节性和趋势性仍然共存,直接混合会互相干扰。因此,先分解再分别用合适方向混合。
第
4.1 序列分解 (SeriesDecomp)
借用 Autoformer 的移动平均核:
- 趋势项 = 移动平均(低频,平滑)
- 季节项 = 残差(高频,周期性波动)
4.2 季节混合 (Seasonal Mixing, Bottom-Up ↑)
为什么 Bottom-Up? 从季节分析角度,大周期是小周期的聚合(Box & Jenkins, 1970):周流量 = 7 个日流量的叠加。细粒度季节信息对粗粒度有补充作用。
公式:
- 输入维度:
(细粒度序列长度) - 输出维度:
(粗粒度序列长度)
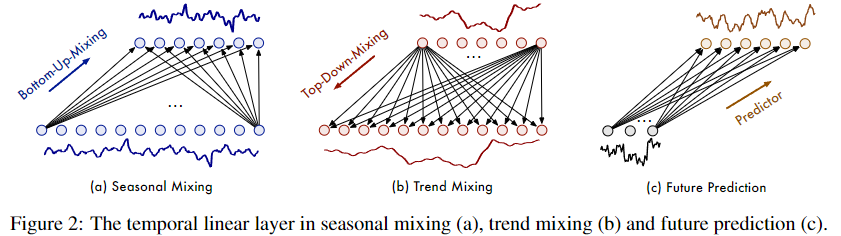
论文 Figure 2:三种线性混合层的示意图。(a) 季节混合(Bottom-Up):底层(细粒度)节点向上连接到更粗的尺度,每个粗粒度节点汇聚细粒度的局部季节信息;连线密集且呈现周期重复的模式(对应论文 Figure 3(a) 中的对角条纹权重矩阵)。(b) 趋势混合(Top-Down):顶层(粗粒度)节点向下广播,每个细粒度节点受粗粒度全局趋势引导;连线集中在对角线(对应 Figure 3(b) 的黄色对角线)。(c) 未来预测:FMM 中每个尺度独立用线性层回归未来序列。
数值示例:季节 Bottom-Up 混合(M=2,P=8)
参数:P=8,M=2,d=1(单特征,不计嵌入维度,仅演示时间维混合)
输入季节成分(经过分解后,带周期规律的序列):
| 尺度 | 序列长度 | 值(体现日内周期,2步一周期) |
|---|---|---|
| s₀ (scale 0) | 8 | [2, -2, 2, -2, 2, -2, 2, -2] |
| s₁ (scale 1) | 4 | [-1, 1, -1, 1](粗粒度,高频被均值池化平滑) |
| s₂ (scale 2) | 2 | [0.5, -0.5] |
Step 1:混合 s₀ → 更新 s₁(Bottom-Up-Mixing 把长 8 映射到长 4)
假设学到的线性层权重等价于"对相邻 2 步取均值后保留相位":
更新:
粗粒度 s₁ 增强了季节振幅:从幅度 1 提升到幅度 1(此例相加后),实际上细粒度提供了准确的相位信息。
Step 2:混合 s₁ → 更新 s₂(Bottom-Up-Mixing 把长 4 映射到长 2)
更新:
验证
- s₂(最粗)的季节振幅从 0.5 → 1.5,增大了 3 倍 ✓
- 细粒度的高频季节信息成功"渗透"到粗粒度,补充了被均值池化抹去的细节 ✓
- 方向 bottom-up:信息流 scale0 → scale1 → scale2,聚合微观到宏观 ✓
4.3 趋势混合 (Trend Mixing, Top-Down ↓)
为什么 Top-Down? 细粒度趋势项受局部噪声影响,容易出现虚假抖动;粗粒度趋势才是真正的宏观走势。用粗粒度引导细粒度,相当于"全局约束局部"。
公式:
- 输入维度:
(粗粒度序列长度) - 输出维度:
(细粒度序列长度)
数值示例:趋势 Top-Down 混合(M=2,P=8)
输入趋势成分(单调上升的宏观趋势):
| 尺度 | 序列长度 | 值(上升趋势) |
|---|---|---|
| t₀ (scale 0) | 8 | [1.0, 1.2, 0.9, 1.5, 1.1, 1.8, 1.0, 2.0](含噪声抖动) |
| t₁ (scale 1) | 4 | [1.1, 1.2, 1.5, 1.5](AvgPool,噪声减少) |
| t₂ (scale 2) | 2 | [1.15, 1.50](最平滑,纯宏观趋势) |
Step 1:混合 t₂ → 更新 t₁(Top-Down-Mixing 把长 2 映射到长 4)
FeedForward 的作用:在通道维度(C 个变量之间)进行信息交互,弥补 S-Mix/T-Mix 只在时间维操作的不足。
五、Future-Multipredictor-Mixing (FMM) 详解
经过 L 层 PDM,得到最终多尺度过去表征
为什么需要多个预测器? 不同尺度的序列主导的时序模式不同(细粒度擅长季节细节,粗粒度擅长趋势)。让每个尺度独立预测,再集成,相当于集成学习(Ensemble)。
每个预测器(
其中
集成:
采用求和而非平均:二者等价(模型可自行学习每个预测器输出的幅度),但求和更直接。
六、训练细节
| 超参数 | 长期预测 | 短期预测 |
|---|---|---|
| 尺度数 M | 3 | 1 |
| PDM 层数 L | 2 | 2(PEMS)/ 4(M4) |
| 16 ~ 128 | 32 ~ 128 | |
| 批大小 | 8 ~ 128 | 32 ~ 128 |
| 学习率 | ||
| 损失函数 | MSE | MSE(PEMS)/ SMAPE(M4) |
| 优化器 | Adam ( | 同左 |
| 训练轮数 | 10 ~ 20 | 10 ~ 50 |
| 硬件 | NVIDIA A100 80GB | 同左 |
设计决策:M 随序列长度增大而增大(性能提升但计算增加);对短序列(M4 输入极短),M=1 避免过度下采样。
七、实验结果
7.1 长期预测(18 个基准)
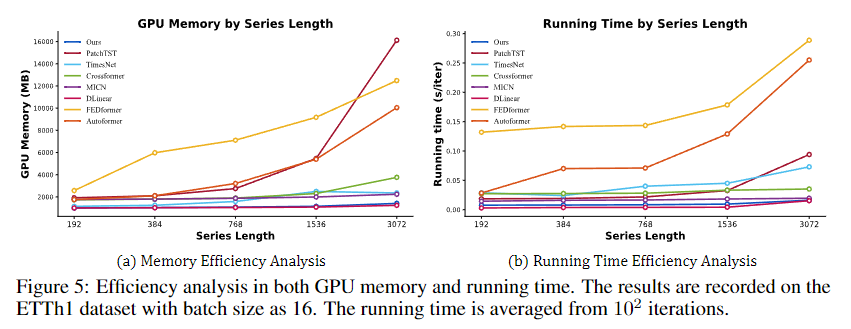
论文 Figure 5:GPU 内存与运行时间的效率对比。(a) GPU 内存:在所有序列长度(192~3072)下,TimeMixer 仅用 ~1000~1400 MiB,远低于 PatchTST(1919~16119 MiB)和 FEDformer(2567~12485 MiB),接近 DLinear 的极简内存占用。(b) 运行时间:TimeMixer 速度与 DLinear 相当(全 MLP 架构优势),约为 PatchTST 的 1/6,Autoformer 的 1/15。
关键数字(Table 2,长期预测,4 个预测长度均值):
| 数据集 | TimeMixer MSE | PatchTST MSE | 提升幅度 |
|---|---|---|---|
| Weather | 0.240 | 0.265 | -9.4% |
| Solar-Energy | 0.216 | 0.287 | -24.7% |
| Electricity | 0.182 | 0.216 | -15.7% |
| Traffic | 0.484 | 0.529 | -8.5% |
| ETTh1 | 0.447 | 0.516 | -13.4% |
| ETTm2 | 0.275 | 0.290 | -5.2% |
TimeMixer 在低可预测性数据集(Solar-Energy, ETT)上仍表现优秀,说明多尺度混合对复杂时序具有鲁棒性。
7.2 短期预测
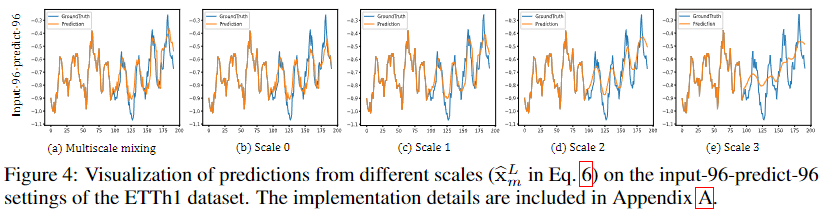
论文 Figure 4:不同尺度预测器的输出可视化(ETTh1,input-96-predict-96)。(a) 多尺度集成结果:最终预测(橙线)紧贴真实值(蓝线),精确捕捉了峰值和低谷。(b) Scale 0(细粒度):捕捉季节细节和短周期波动,但趋势漂移明显。(c)(d) Scale 1/2(中间尺度):平衡细节与趋势。(e) Scale 3(粗粒度):主要捕捉长期宏观趋势,细节模糊。集成后互补,优于任何单一尺度。
短期预测(M4 数据集,OWA 指标,越低越好):
| 频率 | TimeMixer | TimesNet | N-HiTS |
|---|---|---|---|
| Yearly | 0.776 | 0.786 | 0.851 |
| Quarterly | 0.825 | 0.890 | 0.899 |
| Monthly | 0.869 | 0.899 | 0.880 |
| Weighted Avg | 0.840 | 0.851 | 0.855 |
八、消融实验
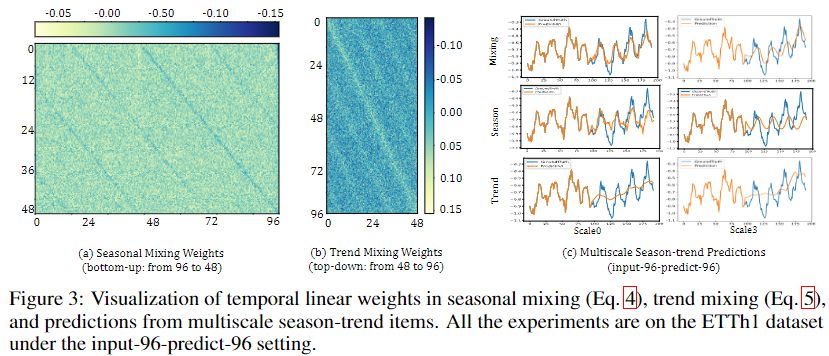
论文 Figure 3:时间线性层权重可视化(ETTh1,input-96-predict-96)。(a) 季节混合权重矩阵(bottom-up,96→48):呈现周期重复的蓝色对角条纹,说明模型学到了"以局部聚合的方式传递季节信息",权重矩阵的周期结构与时序季节性吻合。(b) 趋势混合权重矩阵(top-down,48→96):主要能量集中在黄色主对角线,说明粗粒度趋势被均匀地广播到细粒度,体现"全局平均"的趋势注入。(c) 多尺度季节和趋势预测:细粒度(Scale 0)季节项波动密集,趋势项含噪声;粗粒度(Scale 3)季节项平滑,趋势项清晰上升——验证了不同尺度的功能分工。
消融结果(Table 5,M4/PEMS04/ETTm1 三个基准,越低越好):
| Case | 分解 | 季节混合 | 趋势混合 | 多预测器 | M4 OWA | 说明 |
|---|---|---|---|---|---|---|
| ① 官方设计 | ✓ | Bottom-Up↑ | Top-Down↓ | ✓ | 0.840 | 最优 |
| ② 去除多预测器 | ✓ | ↑ | ↓ | ✗ | 0.925 | FMM 贡献显著 |
| ③ 去除季节混合 | ✓ | ✗ | ↓ | ✓ | 0.962 | 季节混合最关键 |
| ④ 去除趋势混合 | ✓ | ↑ | ✗ | ✓ | 0.941 | 趋势混合也重要 |
| ⑤ 同向混合(均↑) | ✓ | ↑ | ↑ | ✓ | 0.871 | 方向错误降性能 |
| ⑦ 完全反向(均↓/↑) | ✓ | ↓ | ↑ | ✓ | 0.954 | 反向最差之一 |
| ⑩ 无分解+无混合 | ✗ | — | — | ✓ | 0.916 | 无 PDM 大幅下降 |
核心结论:
- FMM(多预测器)缺失导致 OWA 从 0.840 升至 0.925(+10.1%),是第一重要模块
- 季节 Bottom-Up 混合比趋势 Top-Down 混合更重要(去除季节损失更大)
- 方向性是关键:反转方向(case ⑦)导致严重性能下降,验证了"季节 bottom-up + 趋势 top-down"设计的合理性
九、与同类模型横向对比
| 模型 | 架构 | 混合机制 | 分解 | 多尺度 | 长期 SOTA | 短期 SOTA |
|---|---|---|---|---|---|---|
| TimeMixer | 纯 MLP | 时间维(季节↑趋势↓)+ 通道 FeedForward | 季节-趋势 | ✓(M+1 尺度) | ✓ | ✓ |
| PatchTST | Transformer | Token-Mixing(Patch 级自注意力) | ✗ | ✗(单尺度) | 次优 | 一般 |
| TimesNet | CNN | 2D 卷积(时间→周期二维化) | ✗ | 隐式(多周期) | 一般 | ✓(M4 次优) |
| DLinear | 纯线性 | 无混合 | 季节-趋势(预处理) | ✗ | 曾 SOTA | 差 |
| Autoformer | Transformer | Auto-Correlation(频域注意力) | 季节-趋势 | ✗ | 旧 SOTA | — |
| SCINet | CNN | 奇偶分裂 + 交互 | ✗ | ✓(二叉树) | 一般 | ✓(PEMS 曾 SOTA) |
| Pyraformer | Transformer | 金字塔注意力 | ✗ | ✓(层级式) | 差 | — |
TimeMixer 的差异化优势:
- 唯一将多尺度信息融入历史提取(PDM)+ 未来预测(FMM)双阶段的模型
- 纯 MLP 架构 → 无注意力的二次复杂度,内存/速度优势显著
- 分离季节和趋势做方向对立的混合 → 避免噪声相互干扰
十、局限性与未来方向
| 局限性 | 描述 | 可能方向 |
|---|---|---|
| 参数随输入长度线性增长 | 时间维线性层的参数量 ∝ P,移动端不友好 | 注意力/CNN 替代线性混合层 |
| 未建模变量间依赖 | 仅在 FeedForward 中有通道交互,无显式变量关系建模 | 将变量维 Mixing 纳入设计 |
| 理论分析缺失 | 没有理论证明 bottom-up/top-down 设计的最优性 | 谱分析或信息论框架 |
| DFT 分解未被充分探索 | 论文测试了 DFT 分解但性能略差,放弃了 | 未来高频/低频分解可能更准确 |
思考问题
- [ ] 为什么季节成分适合 Bottom-Up 而趋势成分适合 Top-Down?能否从频域角度给出更严格的解释?
- [ ] TimeMixer 的 Predictor_m 对各尺度等权求和——是否应该根据各尺度的预测置信度动态加权?
- [ ] 在极端低可预测性数据集(如 Solar-Energy,forecastability=0.33)上,多尺度混合为何仍有效?各尺度贡献是否均等?
- [ ] TimeMixer 未处理变量间空间依赖(如 PEMS 交通传感器的图结构),能否引入图神经网络增强 FeedForward?
- [ ] PDM 中 SeriesDecomp 使用移动平均,对非平稳序列(股票价格)效果有限——能否用自适应分解(如 EMD)替代?
- [ ] 多尺度下采样(AvgPool)是否损失了过多高频信息?对于噪声大的数据集,是否应在细粒度保留更多历史?
- [ ] TimeMixer 在 M4 竞赛数据(包含 Yearly/Monthly 等多频率)上表现一致最优,这是否说明多尺度本质上是在解决频率泛化问题?
关联笔记
- [[Autoformer-深度学习笔记]] — TimeMixer 直接复用了 Autoformer 的移动平均分解块
- [[PatchTST-深度学习笔记]] — 长期预测主要竞争对手;TimeMixer 在 Weather 上超越 9.4%
- [[DLinear]] — 极简线性基线;TimeMixer 在多尺度上扩展了纯线性思路
- ![[TimeMixer.pdf#page=1|TimeMixer 论文]]