Appearance
DUET 深度学习笔记
DUET: Dual Clustering Enhanced Multivariate Time Series Forecasting(KDD 2025)
一句话定位
DUET = Temporal Clustering Module (TCM) + Channel Clustering Module (CCM) + Fusion Module (FM) 核心洞见:多变量预测的两大顽疾(分布漂移 × 通道异质)可以被"两维聚类"同时攻克——时序维用 MoE 路由不同分布,通道维用频域度量稀疏化注意力。
零、前置知识
0.1 必须了解
| 概念 | 关键内容 | 推荐入口 |
|---|---|---|
| iTransformer | 以变量为 token 的通道依赖 Transformer,DUET 直接在其上扩展 | [[iTransformer-深度学习笔记]] |
| DLinear | 单层 Linear + 序列分解,DUET 每个 MoE 专家是 DLinear 骨架 | [[DLinear-深度学习笔记]] |
| RevIN | 实例归一化 + 可学习仿射;处理训练/测试分布偏移 | [[Autoformer-深度学习笔记]] §RevIN |
| Mixture of Experts (MoE) | 路由网络动态选择专家,Noisy Top-k Gating 平衡负载 | [[iTransformer-深度学习笔记]] |
| Gumbel Softmax | 离散采样的可微分替代;straight-through estimator | 论文附录 A.2 |
| rFFT | 实数输入的快速 Fourier 变换,输出长度 L//2+1 的复数频谱 | 论文附录 A.3 |
0.2 推荐了解
| 概念 | 为什么推荐 |
|---|---|
| Mahalanobis 距离 | CCM 的核心度量:带可学习矩阵 A 的广义欧氏距离 |
| Bernoulli 重参数化技巧 | Gumbel-Bernoulli 采样使离散 0/1 掩码可反向传播 |
| Channel-Hard-Clustering (CHC) | DUET 对比的基线策略:硬聚类 + CD 方法,对比理解 CSC 优势 |
0.3 背景:iTransformer 留下了什么问题
iTransformer 解决了"用谁建模通道依赖"的问题(以变量为 token + 变量轴注意力),但留下两个未解决的矛盾:
- 分布漂移(Temporal Distribution Shift, TDS):同一个线性层面对不同分布区间(趋势/平稳/振荡)效果差,单一模型参数无法同时拟合多种分布形态。
- 通道异质性(Channel Heterogeneity):iTransformer 让所有变量两两注意力——但现实中有些变量高度相关(如温度与湿度),有些几乎独立(如温度与 AQI);强行让噪声通道参与注意力反而引入干扰,降低泛化。
DUET 的解法:双聚类——时序维 MoE 聚类解决 TDS,通道维频域度量聚类解决异质。
一、问题定义
多变量时序预测:给定历史
关键符号:
| 符号 | 含义 |
|---|---|
| 第 | |
| 第 | |
| 通道数(多变量维度) | |
| 历史序列长度(look-back window) | |
| 预测步长 | |
| MoE 专家数(Linear Pattern Extractor 数量) | |
| 隐层维度(d_model) | |
| top-k 激活专家数(通常 k=1) |
DUET 整体前向公式:
二、整体架构鸟瞰
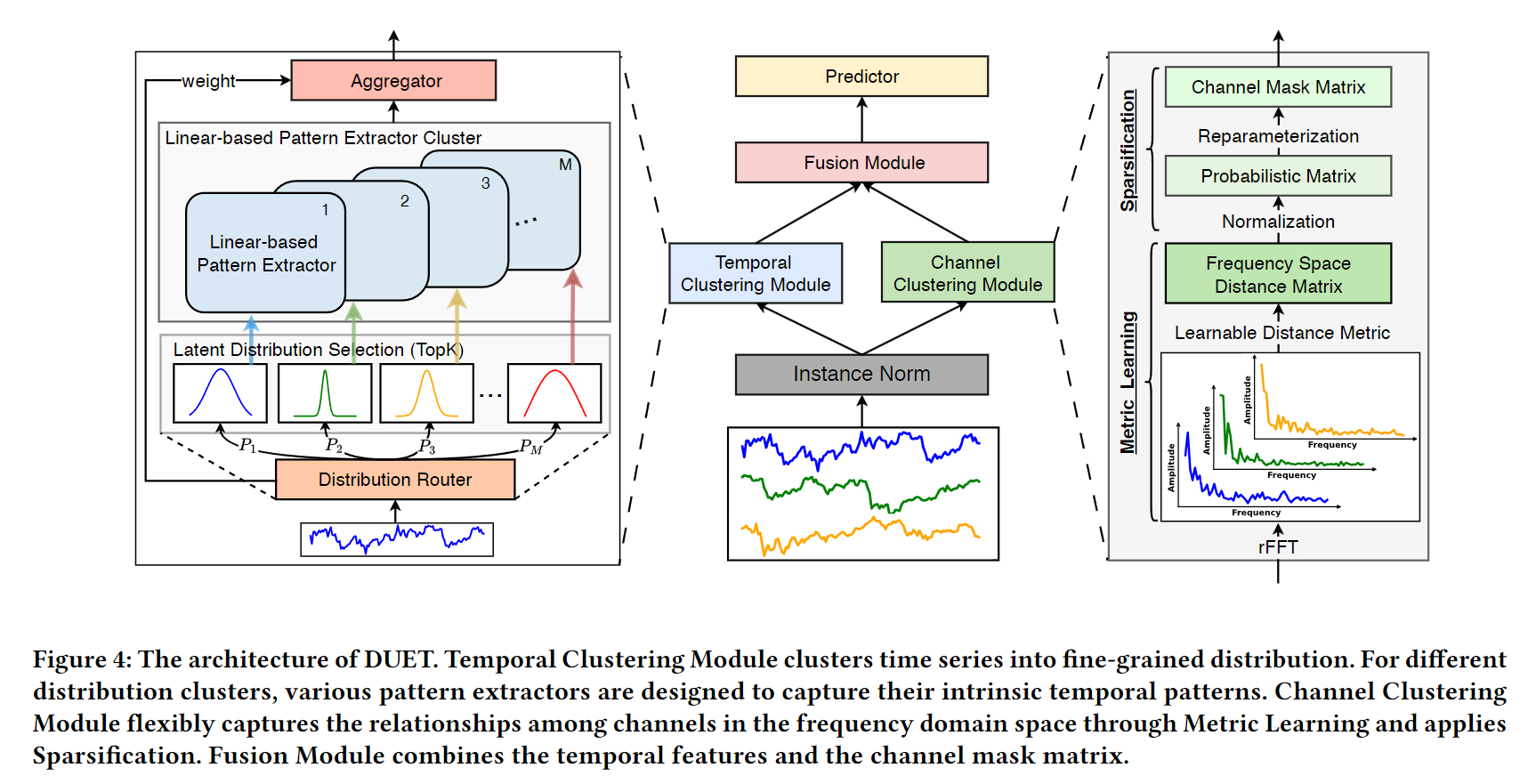
论文 Figure 4:DUET 整体架构。左侧是 TCM——Distribution Router 把每条时序映射到 M 个潜在分布之一,对应的 Linear-based Pattern Extractor 负责提取该分布下的时序特征;多个 Extractor 输出经 Aggregator 按 gate 权重加权聚合,得到
。右侧是 CCM——对时序做 rFFT 取幅度谱,用可学习 Mahalanobis 矩阵计算通道两两距离,归一化为概率后经 Reparameterization 生成 0/1 Channel Mask Matrix 。中央是 FM——以 为 Q/K/V,叠加 做 Masked Attention,稀疏地融合跨通道信息,最终通过线性头输出预测。
![[assets/arch_dataflow.svg]]
颜色语义:🔵蓝=输入/输出,🟠橙=归一化/投影,🟣紫=注意力,🔴红=可学习度量/Gumbel采样,🟢绿=预测头,🩵青=频域变换,⬛深灰=中间特征。
数据流摘要(CI=True 模式,默认):
X (B,T,N)
→ InstanceNorm
├─ TCM路径: rearrange→(B·N,T,1) → RevIN norm → Distribution Router → SparseDispatch
│ → M个Linear Expert各自处理 → Aggregator → X^temp (B,N,d)
└─ CCM路径: rearrange→(B,N,T) → rFFT → Mahalanobis 距离 → Gumbel-Bernoulli → M (B,1,N,N)
→ FM: Masked Multi-head Attention(X^temp, M) + FFN + ResConn
→ Linear head (d→F)
→ RevIN denorm
→ Ŷ (B,F,N)三、Temporal Clustering Module(TCM)
做什么:把每条时序路由到与其分布最匹配的"专家"(独立 DLinear),从而让不同分布区间的序列走不同的线性变换路径,解决 TDS。
3.1 Distribution Router
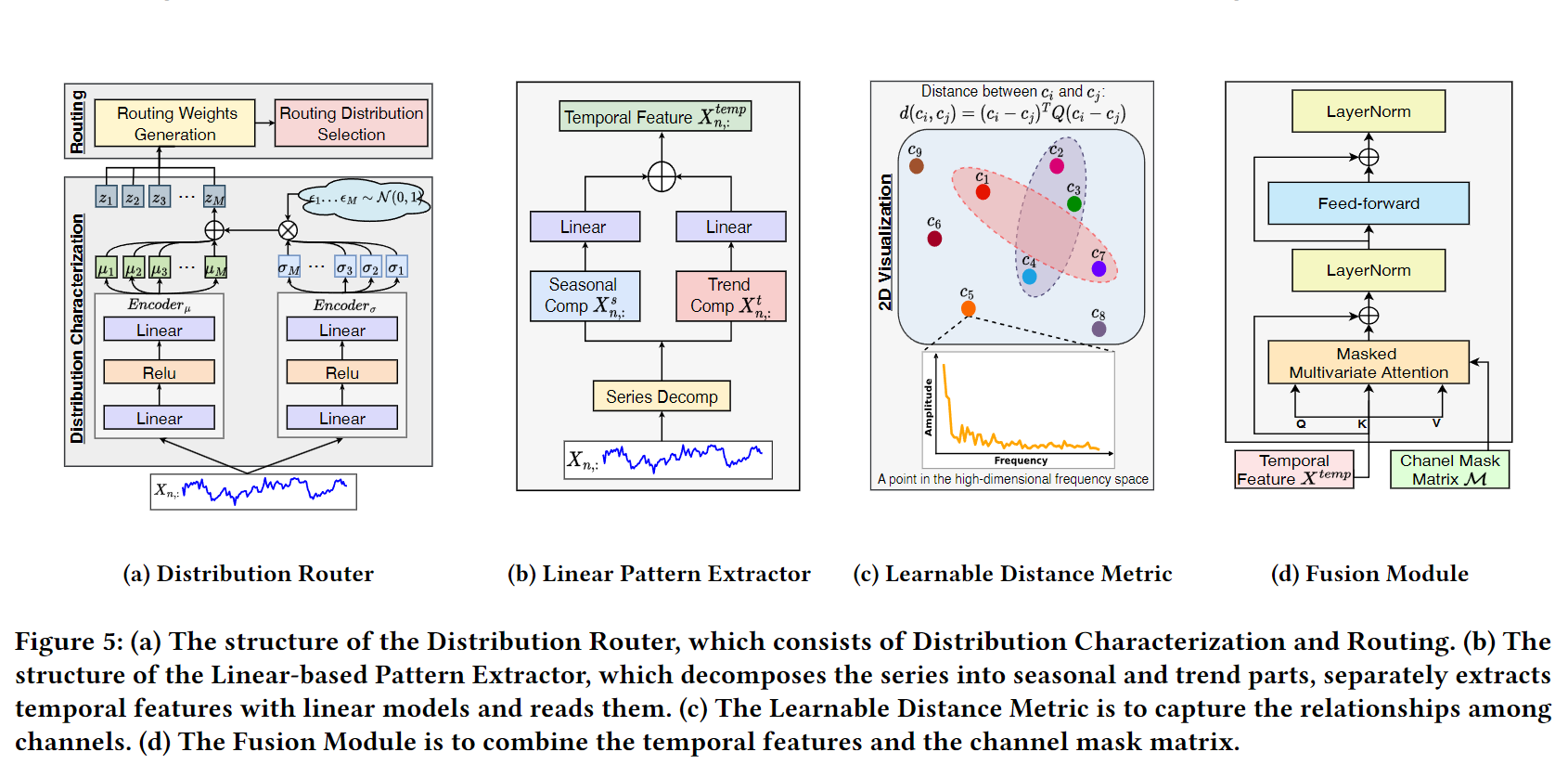
论文 Figure 5:(a) Distribution Router = Distribution Characterization(两路 Encoder 分别预测均值μ和标准差σ)+ Routing Distribution Selection(Noisy Top-k Gating)。(b) Linear Pattern Extractor = series_decomp 分离 seasonal/trend 后各过独立 Linear,两路输出相加得到时序特征向量(维度 d_model,非 pred_len)。(c) Learnable Distance Metric——在高维频率空间中,每个通道是一个点(频谱幅度向量),可学习矩阵 Q=A^T A 定义点之间的距离函数。(d) Fusion Module——以时序特征
为 Q/K/V,叠加 Channel Mask Matrix 做 Masked Multivariate Attention。
Distribution Characterization(借鉴 VAE reparameterization trick):
其中
为什么用 μ+ε⊙Softplus(σ) 而非直接 MLP?
这是 Noisy Gating 的精妙改写:原始 Noisy Gating 在 clean logits 上加高斯噪声
,但 stddev 由另一个网络生成(需 softplus 保正)。这里把 reparameterization trick 的加噪过程与 Noisy Gating 合并: 本质上是带数据自适应噪声的 logit,训练时引入探索(噪声),推理时可固定 ε=0(或用均值路径)。论文附录 A.2 证明二者等价。
Noisy Top-k Gating(路由决策):
数值示例:Distribution Router(T=8, M=4, k=1)
输入(单条序列
(强上升趋势序列)
Step A:Distribution Characterization
设
添加重参数化噪声后
Step B:Top-1 Gating
KeepTopK 仅保留最大值:
Softmax 后:
路由结果
- 上升趋势序列 → Expert 0(捕捉趋势模式的线性层)
- 若换成振荡序列(如正弦波),Encoder 感知不同μ/σ,路由到不同 Expert
- 负载均衡损失
惩罚所有样本都涌向同一 Expert
3.2 Linear Pattern Extractor(单个专家)
每个专家独立地对被分发来的序列提取时序特征:
序列分解(移动平均):
时序特征提取(两路独立 Linear,输出 d 维特征):
其中
参数命名歧义
代码中
self.pred_len = configs.d_model——这个"pred_len"实际是 d_model(隐层维度),Linear 的输出维度是 d_model,不是预测步长!请注意区分。
Aggregator(加权聚合 k 个专家输出):
最终
3.3 MoE 负载均衡损失
importance[e] = 所有样本分配给 Expert e 的 gate 权重之和;load[e] = Expert e 处理的样本数。两者变异系数越大,说明负载越不均匀,损失越大,梯度推动路由更分散。
四、Channel Clustering Module(CCM)
做什么:在频域计算通道两两相似度,用可学习 Mahalanobis 矩阵参数化"哪些频率分量更重要",通过 Gumbel-Bernoulli 可微分采样生成 0/1 稀疏掩码,只让相似通道互相注意。
4.1 频域幅度提取
rFFT 对实数序列输出
为什么用频域而不是时域? 频域幅度
4.2 Learnable Mahalanobis 距离
其中
代码实现:
python
diff = XF.unsqueeze(2) - XF.unsqueeze(1) # (B, N, N, F)
temp = torch.einsum("dk,bxck->bxcd", self.A, diff) # A 变换 diff
dist = torch.einsum("bxcd,bxcd->bxc", temp, temp) # ‖A·diff‖²数值示例:Mahalanobis 距离(B=1, N=3, T=8, F=5, A=I)
频谱幅度(归一化后):
| 通道 |
差向量:
距离(A=I):
相似度 → 概率:
验证
- C0 和 C1 频率成分完全一致 → 距离=0 → 相似度极高 → 掩码概率趋向 1(允许注意力)✓
- C0 和 C2 频率成分完全不同 → 距离较大 → 相似度低 → 掩码概率低(倾向屏蔽)✓
- 可学习 A 会在训练中自动调整哪些频率轴对预测相关性更有判别力
4.3 归一化与对角线处理
最终
4.4 Gumbel-Bernoulli 可微分采样
核心思路:每个通道对
python
logit₁ = log(p/(1-p)) # "attend" 的 logit
logit₀ = log((1-p)/p) # "不 attend" 的 logit
new_matrix = [logit₁, logit₀] # shape (N*N, 2)
sample = gumbel_softmax(new_matrix, hard=True)[..., 0] # 0/1 离散采样,梯度可导前向:argmax → 0/1 one-hot(离散) 反向:softmax 梯度(连续)→ straight-through 流回 A 的梯度
数值示例:Gumbel 采样(p=0.85)
加 Gumbel 噪声(
→ argmax 选 class 1 → mask = 1(允许注意力) ✓
验证
p=0.85 高概率时,logit₁≫logit₀,即使加噪声大概率仍选 class 1,掩码约 85% 概率为 1 ✓
最终
五、Fusion Module(FM)
做什么:以
5.1 Masked Multivariate Attention
代码实现(large_negative = -math.log(1e10) ≈ -23.03,避免 softmax NaN):
python
attention_mask = torch.where(attn_mask == 0, -23.03, 0)
scores = scores * attn_mask + attention_mask
# mask=1处: scores × 1 + 0 = 原始分数
# mask=0处: scores × 0 + (-23.03) → softmax后≈0数值示例:Masked Attention(B=1, N=4, d=2, H=1)
注意力分数矩阵(未归一化):
设 Channel Mask(C0 和 C2 无关,C1 和 C3 无关):
掩码后(mask=0 处替换为 -23.03):
Softmax 后(C2 权重 ≈ 0):
验证
- C0 仅聚合 C1 和 C3 的信息(C2 被屏蔽)✓
- C1 仅聚合 C0、C2 的信息(C3 被屏蔽)✓
- 掩码位置 softmax 权重 ≈ 0,实际上不参与信息传播 ✓
5.2 FM 完整结构(Transformer Block)
每层 EncoderLayer 结构与标准 Transformer 相同,差异在于掩码:
x (B,N,d) → [Masked Multi-head Attention] → +x → LayerNorm
→ [FFN: Conv1d(d→d_ff) + GELU + Conv1d(d_ff→d)] → +x → LayerNorme_layers=2:第 1 层让每个变量聚合强相关邻居特征,第 2 层做二阶聚合(邻居的邻居)。
输出投影:
六、训练细节
损失函数:
DUET._process() 返回的 additional_loss 中,由 TFB 框架自动叠加到主损失。
关键训练技巧:
- L1 loss(MAE)作为优化目标,Adam optimizer,初始 batch_size=64(OOM 时自动减半至最低 8)
- CI=True(Channel-Independent MoE):B×N 条序列独立通过专家路由,参数量轻,默认设置
- RevIN 先 norm 后 denorm,仿射参数 (weight, bias) ∈
是每个通道独立可学习的
超参数(重要的):
| 超参 | 默认值 | 含义 |
|---|---|---|
| M (num_experts) | 4 | MoE 专家数,同领域数据集最优值相同(如 ETTh1/ETTh2 都是 4) |
| k | 1 | top-k 激活专家数(论文实验均用 k=1) |
| e_layers | 2 | FM 中 Transformer 层数 |
| d_model | 可变 | 专家输出维度 = 变量 token 维度 |
| moving_avg | 25 | series_decomp 滑动平均窗口(奇数) |
七、实验结果
![[assets/DUET/figure3-radar-performance.png]]
论文 Figure 3:10 个常用数据集上的 MSE 雷达图(所有预测步长平均)。DUET(红线)在 ETTh1、ETTh2、ETTm2、Solar、Traffic 上均优于所有 baseline,整体雷达面积最小(MSE 越低越好)。特别在 Solar(强通道相关)和 Traffic(强分布漂移)数据集上领先显著,验证 CSC 策略和 TCM 的设计价值。
主实验关键数字(来自 Table 3,预测步长平均):
| 数据集 | DUET MSE | 次优 | 提升 |
|---|---|---|---|
| ETTh2 | 0.334 | PDF 0.337 | -0.9% MSE |
| ETTm2 | 0.247 | iTransformer 0.254 | -2.8% |
| Solar | 0.169 | PDF 0.200 | -15.5% |
| Traffic | 0.360 | PDF 0.368 | -2.2% |
总体:DUET 在 30 个 benchmark 配置中排名第 1,次优 PDF 仅 8 次第 1。对次优 baseline PDF 平均 MSE 降低 7.1%,MAE 降低 6.5%。
八、消融实验
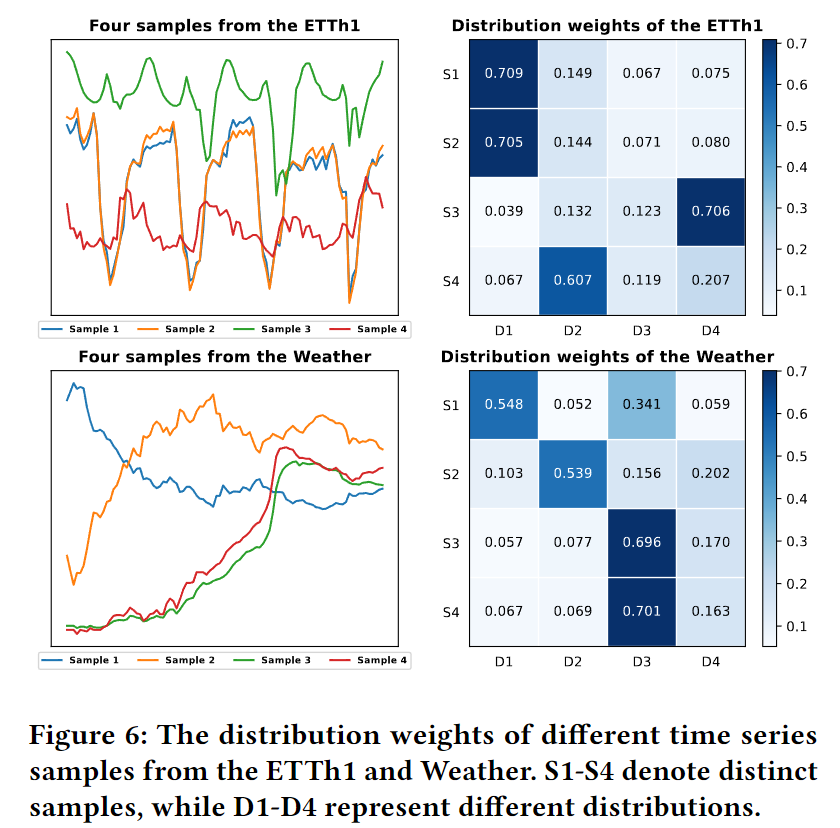
论文 Figure 6:ETTh1 和 Weather 各 4 个样本的专家权重热力图(纵轴=样本,横轴=4个专家 D1-D4)。ETTh1 的样本 1 和 2 具有相似季节性模式,分布权重也相似(主要路由到 D1);而样本 3 和 4 分布截然不同,权重主要在 D4。Weather 样本 3 和 4 趋势相似却分布权重大相径庭,说明 TCM 真正捕捉了分布特征而非时间对齐。
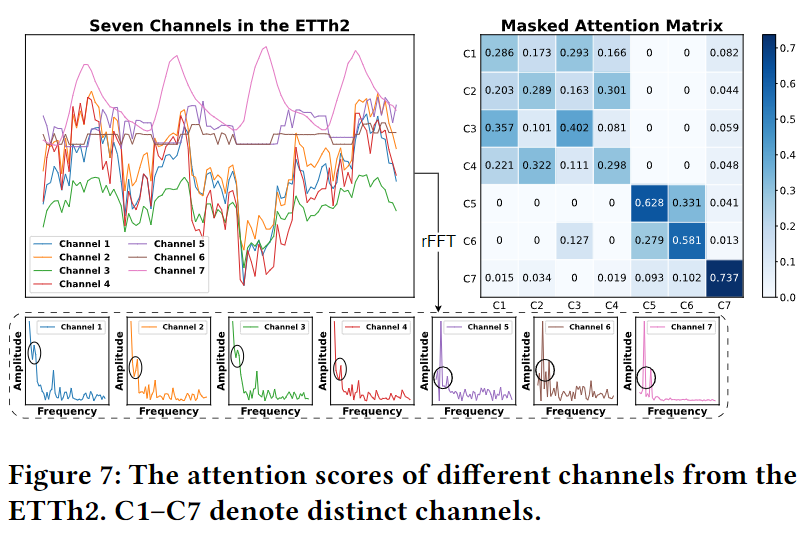
论文 Figure 7:ETTh2(7 个通道 C1-C7)的 Masked Attention 权重矩阵(右侧热力图)。左侧是 7 个通道的频谱图和对应时序。颜色越深=注意力权重越大。可见具有相似频率成分的通道(如 C1 和 C2)被聚为软组(深色格子),跨组之间保留少量权重(如 C3 和 C6 之间的 0.127),兼顾了组间信息传递,这是 CSC 优于 CHC 的关键:不强制硬边界,弱相关通道对可保留小权重。
消融结论(Table 2):
| 移除组件 | ETTh2 MSE 变化 | 关键发现 |
|---|---|---|
| w/o TCM | 0.334 → 0.344 (+3.0%) | TCM 对分布变化大的数据集(ETTh2)影响显著 |
| w/o CCM | 0.334 → 0.391 (+17.1%) | CCM 对强通道相关数据集(Traffic)影响最大 |
| Full Attention(不掩码) | 0.334 → 0.344 (+3.0%) | Bernoulli 掩码 > 全连接,噪声通道危害已证实 |
| Temporal Info(时域距离) | 0.334 → 0.345 (+3.3%) | 频域度量比时域度量更鲁棒 |
九、看-back Window 敏感度
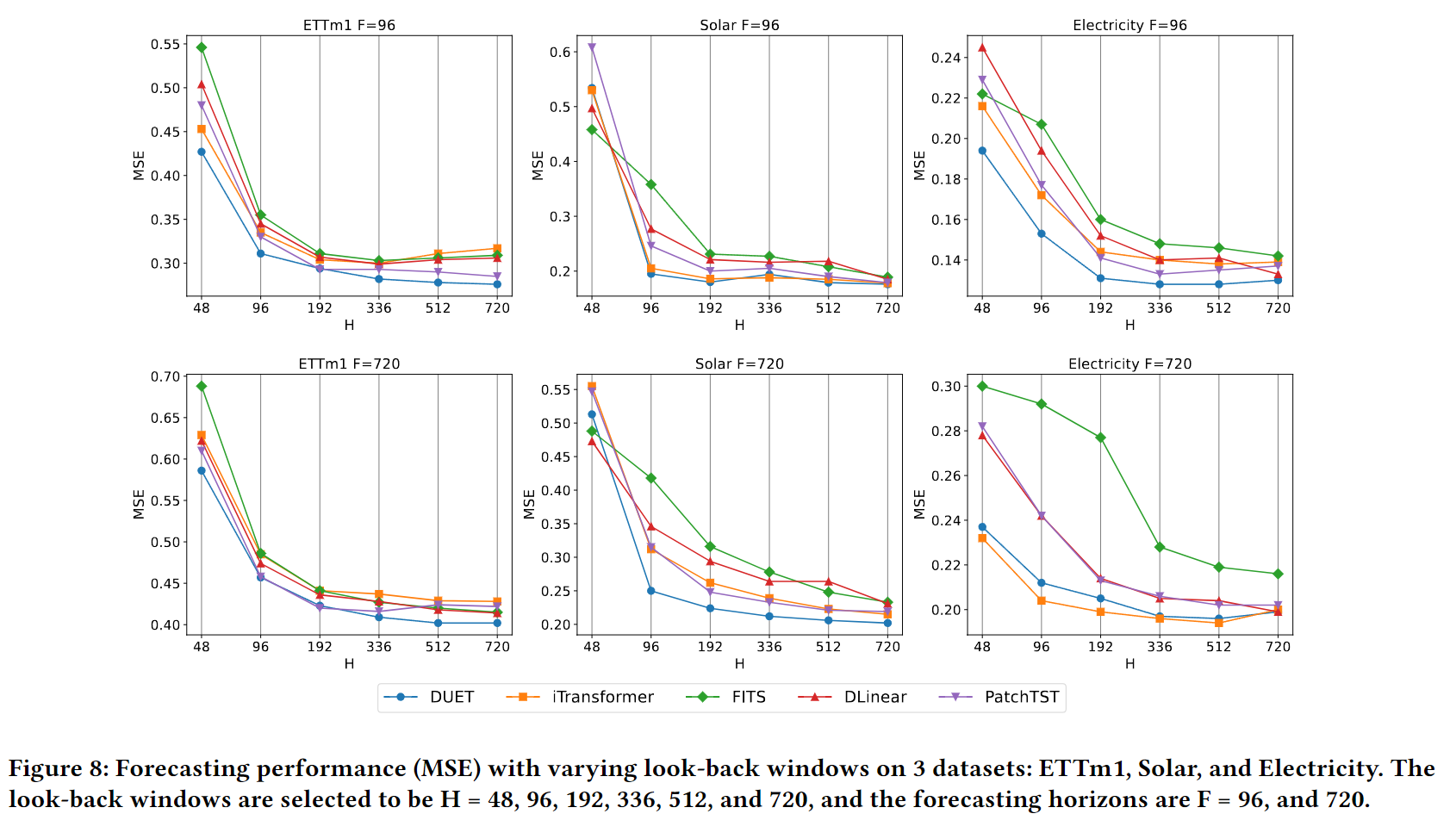
论文 Figure 8:ETTm1、Solar、Electricity 三个数据集在预测步长 F=96 和 F=720 下,随看-back window H(48→720)增大的 MSE 变化。DUET(蓝线)在所有设置下始终优于 iTransformer、FITS、DLinear、PatchTST,且随 H 增大持续受益,说明 DUET 能有效利用长历史序列——这得益于 TCM 的多专家路径允许不同时段分布独立建模,而非用单一线性层强行拟合全部历史。
十、与同类模型横向对比
| 维度 | DLinear | iTransformer | PatchTST | CHC(DGCformer) | DUET |
|---|---|---|---|---|---|
| Token 语义 | 无 | 变量 | 时间 patch | 变量(硬聚类) | 变量 |
| 注意力轴 | 无 | N×N | P×P | cluster 内 N×N | N×N(稀疏) |
| 通道策略 | CI | CD(全连接) | CI | CHC(硬边界) | CSC(软聚类) |
| 分布漂移 | ❌ 静态线性 | ❌ 静态 | ❌ 静态 | ❌ 静态 | ✅ MoE 路由 |
| 通道选择度量 | ❌ | ❌ | ❌ | ❌ 规则式 | ✅ 可学习 Mahalanobis |
| 归一化 | 无 | 无 | Instance | 无 | RevIN (affine) |
| 时间复杂度 | |||||
| 额外辅助损失 | ❌ | ❌ | ❌ | ❌ | ✅ MoE 负载均衡 |
DUET vs. CHC(DGCformer)的本质区别: CHC 用规则(图聚类相似度阈值)分硬组,组间完全隔离;DUET 的 CSC 是软掩码——高相似度通道权重大(接近 1),低相似度权重小但非 0,保留跨组的弱信息流。且 DUET 的度量完全数据驱动(A 可学习),无需人工规则。
十一、局限性与未来方向
| 局限 | 描述 | 可能方向 |
|---|---|---|
| 计算开销 | FM 仍是 | 稀疏注意力(只对 mask=1 的通道对计算) |
| 超参 M 敏感 | 不同领域最优 M 不同(ILI 最优 M=2,ETT 最优 M=4),需调参 | 自适应确定 M 的数量(如 BIC/MDL 准则) |
| 频域假设 | CCM 假设通道相似度体现在频域幅度;对强非平稳数据(频谱随时间变化)可能失效 | 短时 Fourier 或小波替代 rFFT |
| k=1 的稀疏性 | top-1 路由每个样本只走 1 个专家,表达能力受限 | top-2/3 路由(需平衡训练代价) |
思考问题
- [ ] CCM 中 A 矩阵的秩/稀疏结构在训练后是什么样的?是否出现"专注少数关键频率"的模式?
- [ ] 当 M=1 时 TCM 退化为单一 DLinear,性能对比 DLinear 的差值是否完全来自 CCM?能否设计消融验证?
- [ ] Gumbel-Bernoulli 的 hard=True 在推理时是否应改为 hard=False(软掩码),以减少随机性带来的预测方差?
- [ ] CI 模式下 B×N 条序列独立路由——同一变量在不同 batch 样本中可能被路由到不同专家,这个"变量级路由不一致"是否会在长序列预测中引入噪声?
- [ ] CCM 的频域距离是全局计算的(整段历史),能否扩展为局部时窗距离(类似短时 Fourier),以处理通道关系随时间变化的场景(如节假日前后相关结构不同)?
- [ ] DUET 中 RevIN denorm 在
cluster.revin中完成,但 RevIN 的统计量是从(B,T,N)格式收集的——CI 模式下 MoE 处理完后是(B,d,N)格式,denorm 时维度对齐是否有潜在 bug 风险?(提示:RevIN 统计量沿 dim=1 即时间轴,denorm 的是预测轴 pred_len,两者语义不同但代码复用了同一 RevIN 对象)
关联笔记
- [[iTransformer-深度学习笔记]] — DUET 直接承接 iTransformer 的变量-token 设计,解决其未处理的 TDS 和通道异质
- [[DLinear-深度学习笔记]] — DUET 每个 MoE 专家本质是 DLinear(seasonal/trend 两路 Linear)
- [[Autoformer-深度学习笔记]] — series_decomp(移动平均分解)源自 Autoformer
- [[PatchTST-深度学习笔记]] — CI 策略的代表,DUET 对比中展示了 CSC > CI 的场景
- ![[DUET.pdf#page=1|DUET 论文]]